Organising data in spreadsheets
Overview
Teaching: 20 min
Exercises: 0 minQuestions
How do we organise and format data in spreadsheets for effective data use?
Objectives
Describe best practices for data entry and formatting in spreadsheets.
Apply best practices to arrange variables and observations in a spreadsheet.
A common mistake is use a spreadsheet like a lab notebook. In other words, to convey information not just with the data, but with notes in the margin and the spatial layout of the data. We humans can (usually) interpret these things, but computers cannot. They are incredibly literal, so unless we explain every single nuance of meaning that we intended, the computer will misinterpret our data - and that causes problems. This is why it is extremely important to start with well-formatted tables from the outset - before you even start entering data from your first preliminary experiment.
Data organisation is the foundation of your research project. It can make it easier or more difficult to work with your data (for yourself and others) throughout your analysis. You should start thinking about data organisation even before you start collecting data. There’s a lot of flexibility, but some of the choices you make now will limit your ability to work with the data in the future.
Best data formats may differ
The best layout for data entry might change dependent on the specific use case. Do not stick to a format just because you have used it previously. Choose the best format on a case-by-case basis. (And if you need to convert between formats, ideally you should automate the conversion with a script in, say, Python or R.
Structuring data in spreadsheets
Here are some cardinal rules when using spreadsheet programs for data organisation:
- Put each of your variables (i.e. the things you are measuring or observing, like ‘weight’ or ‘temperature’) in its own column. Put a single observation of these variables in its own row. Keep your data in a nice and tidy table structure.
- Include metadata about your data with your data (but not in your data).
- Leave the raw data raw - do not change it! This means anything you do to your data (even sorting it) - do it on a copy or you will change the original data irreversibly and will not be able to go back.
- Keep track of your analyses.
- Export the cleaned data to a text-based format like CSV (comma-separated values). This ensures that anyone can use the data, and is required by most data repositories and publishers. We will cover this later in the lesson.
Let’s have a look at each of these rules in action.
Tidy data principle
Do not try to combine multiple variables in one cell and do not put multiple observations of the same variable in the same row. Let’s look at the following data from a survey of small mammals in a desert ecosystem. Different scientists have gone to the field and entered data into a spreadsheet. They kept track of variables like species, plot, weight, sex and date when data was collected. Here’s an example of poor data organisation:
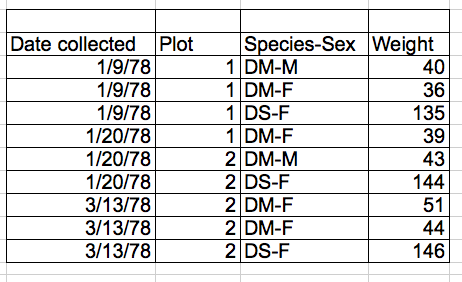
There are problems like the species and sex variables being in the same field. This data format would make it difficult to easily look at all of one species, or look at different weight distributions by sex. If, instead, we put sex and species in different columns, it would be much easier to perform such analyses.
The same data could be better organised as:
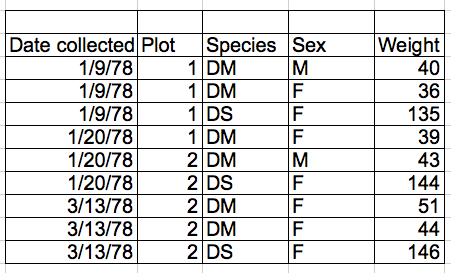
Columns for variables and rows for observations
The rule of thumb, when setting up data in a table is: columns = variables, rows = observations, cells = data values.
Including metadata with the data
“Metadata” is the data you record about your data (such as the date the experiment was conducted, who conducted it, etc). It is essential to understanding the circumstances under which your data was collected. You may be on intimate terms with your dataset while you are collecting and analysing it, but this will change over time. After six months, you are unlikely to remember the exact algorithm you used to transform a variable, or that “sglmemgp” means “single member of group”. You don’t need a photographic memory if you collect good metadata.
Your data is important, which means there will be many people who will want to examine it. They will need good metadata if they are to understand your findings, review your submitted publication, replicate your results, design a similar study, or even just want to archive your data. While digital data by definition are machine-readable, understanding their meaning is a job for human beings - and they need the help that metadata provides. The importance of documenting your data during the collection and analysis phase of your research cannot be overstated - it is fundamental.
Metadata should not be contained in the data file itself, because it can disrupt how programs interpret your data file.
Rather, metadata should be stored as a separate file in the same directory as your data file, preferably in plain text
format (i.e. .txt) with a name that clearly associates it with your data file. Because metadata files are free text format,
they allow you to encode comments, units, information about how null values are encoded and related information.
An alternative is to create a separate README tab in your spreadsheet with the metadata (but make sure you also export it when you export your cleaned data in e.g. CSV file format).
Additionally, file or database level metadata describes how files that make up the dataset relate to each other; what format they are
in; and whether they supersede or are superseded by previous files. A folder-level README.txt file is the classic way of accounting for
all the files and folders in a project.
Credit: MANTRA
The above text on metadata was adapted from the online course Research Data MANTRA by EDINA and Data Library, University of Edinburgh. MANTRA is licensed under a Creative Commons Attribution 4.0 International License.
Keeping your raw data - raw
Never modify your original (raw) data - create a new file or a new tab with a copy of your data before you start transforming and cleaning your raw data. This includes even sorting your data as sometimes you can (accidentally or intentionally) sort a single column without expanding the sort to other columns and forget about it - if you save your data after this step this will change it irreversibly.
Keeping track of your analysis
When you are working with data in spreadsheets, the spreadsheet you end up with will often look very different to the one you started with. With each change, you are losing information about the history of the data. How many times have you needed to roll back an analysis, only to become completely lost when retracing your steps? There are ways of mitigating this problem:
- Before starting your analysis, create a new copy of the original data file to keep alongside your analysed data. This way, you will always be able to check changes against your original dataset and, if the worst comes to the worst, it will be easy to start the analysis again!
- Record the steps you take as you conduct your analysis. You should record these steps as you would any step in an experiment. We recommend that you do this in a plain text file stored in the same folder as the data file.
In the following example, the spreadsheet has ‘raw’ tabs in which to store the original, untouched data and ‘clean’ tabs in which the processed data is stored. It is accompanied with a text file that describes the steps that have been taken.
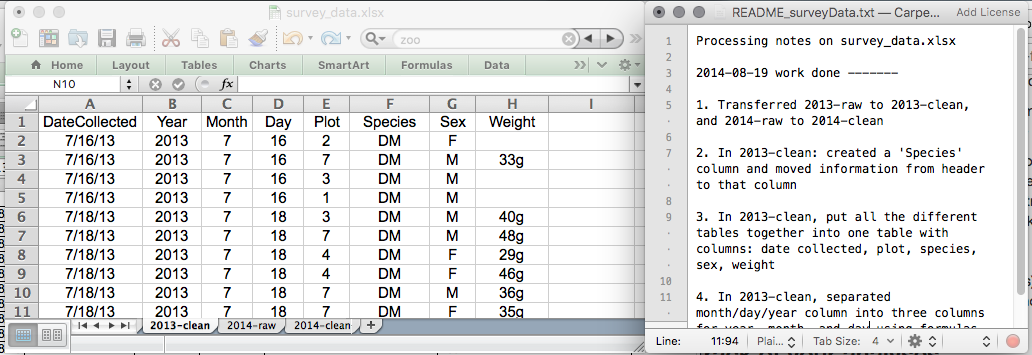
Version controlling your data
Although out of scope for this lesson, you can learn about version control in a separate course, which can be used to record the transformation of your data over time, and provides tools to roll back to any previous version of the data.
Fixing mistakes in data organisation
We will now look at some common mistakes and learn some best practices in data organisation that will help us keep our data clean and tidy.
Key Points
Organise your data according to the tidy data principles.
Never modify your raw data. Always make a copy before making any changes.
Keep track of all of the steps you take to clean your data in a plain text file.
Record metadata in a separate plain text file (such as README.txt) in your project root folder or folder with data.